![]()
DeepSeek keeps finding ways to insert itself into conversations about AI, and its latest move is the V4 preview. The Hangzhou-based company just dropped two new models, and they’re already outperforming some well-known American alternatives in specific benchmarks.

The two models are V4-Pro, which runs in Expert mode, and V4-Flash, which runs in Instant mode. V4-Pro is the biggest of the two at 1.6 trillion parameters, while V4-Flash sits at 284 billion. Both support a one-million-token context window, which puts them in the competitive range with the top options currently available.
The New DeepSeek V4 Capabilities
Both models are open source. You can download them directly from Hugging Face and run them on your own hardware. The catch with V4-Pro is its size; at 1.6 trillion parameters, you’ll need a serious amount of VRAM to get it running locally.
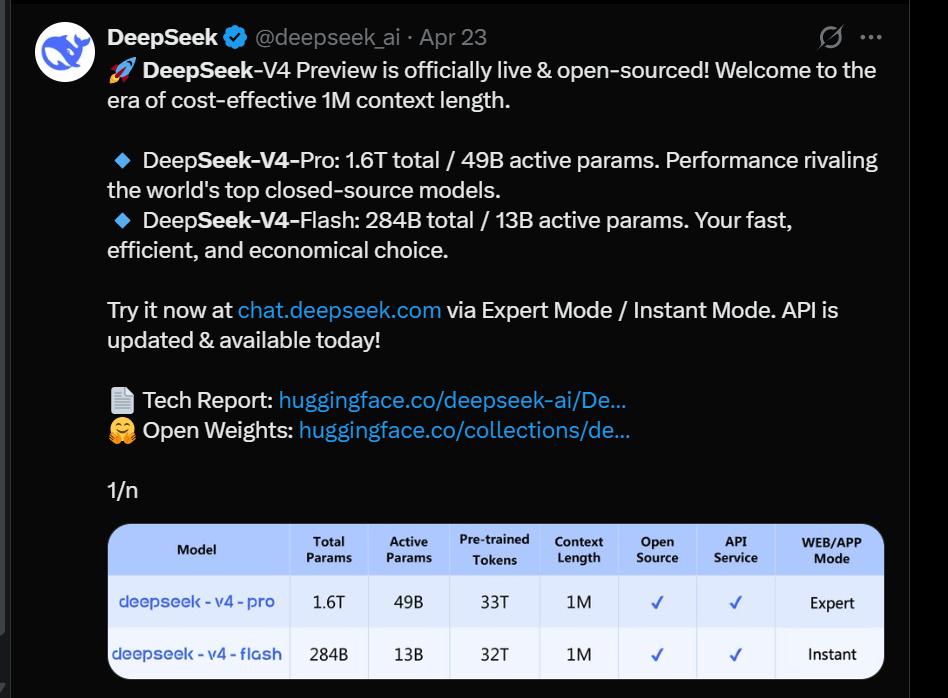
The benchmark comparisons are where things get interesting. DeepSeek put V4-Pro up against Gemini, ChatGPT, and Claude, and the results are hard to ignore.
On Codeforces, a platform used to measure competitive programming ability, V4-Pro scored 3,206. That beats GPT-5.4’s 3,168 and Gemini 3.1’s 3,052, which puts V4-Pro at the top of the open-source category for coding tasks.
You may also like: ChatGPT Age Prediction System Now Rolling Out to Identify Teen Users
On LiveCodeBench, V4-Pro scores 93.5, which clears Claude Opus 4.6 at 88.8 and Gemini at 91.7. The pattern holds for agentic tasks too. On Toolathlon, V4-Pro hits 51.8, ahead of Claude’s 47.2 and Gemini’s 48.8.
What stands out about V4-Flash is that it keeps up with V4-Pro on simpler agent tasks while using far less compute. If you don’t need the full weight of V4-Pro, V4-Flash gives you comparable results at a much lower cost.
Where does V4-Pro perform better than the competition?
DeepSeek’s new models don’t win everywhere. Claude Opus 4.6 still leads on long-context retrieval, scoring 92.9 on MRCR 1M compared to V4-Pro’s 83.5. GPT-5.4 also holds the top spot on Terminal Bench 2.0 with 75.1, while V4-Pro lands at 67.9.
You may also like: Anthropic Launches Claude for Healthcare with Personal Health Data Integration
Where DeepSeek pulls ahead is pricing. V4-Pro costs $3.48 per million output tokens. OpenAI charges $30, and Anthropic charges $25 for comparable workloads. That’s not a small gap. For developers building AI-powered products and watching their API costs, that difference changes the math significantly.